Indexing good content - not junk
By Alex Chudnovsky (Published: 5 Nov 2005)
Foreword
The World Wide Web is growing very fast, so fast in fact that nobody seems to know how big it is. Only when search engines grow their indices it becomes clear that the web is pretty big. This does not happen often however and there is a very good reason for it - data sizes are huge even for companies with billions of dollars in their bank accounts. The choice for smaller players is therefore to not even try to compete with the big guys in the game of web searching. Most search engines choose to limit their attention to a particular country or some industry like technology. This is done to reduce complexity of the task at hand and therefore gain a chance to build a niche but competitive search engine. Here, at Majestic-12, we face similar problem that will only get worse. But in our attempt to solve this problem we don't want to follow the path that will lead to a niche search engine because people search for various topics and its just plain not convenient to change or even remember different search engines. This means we will have to be smart and non-conventional - what's the point in being boring and predictable otherwise?
Situation analysis
There are many websites out there that offer valuable content but their pages are also full of junk - ads, navigation bars, and lots of links and links and links. Humans are smart enough to ignore most of that junk without thinking twice about it and focus on good content that is present on a page. Search engines or more precisely indexers are not that smart and they pick up all the data that humans ignore so easily. The implications of indexing junk for the search engine are very considerable:
- Bigger data sizes: this is the most immediate result as more storage needed to keep crawled data and final index is bigger
- Slower processing: this is the direct result of having more data as processing it will require much more efforts
- Less relevancy: due to junk indexed it will inevitably make searches less relevant, especially due to spam
Typical no-brainer solution is just throw more hardware and take the hit with inevitable increase in costs. Another way is to reduce the task by rejecting all pages apart from some niche market (ie French only pages). This not the Majestic-12 of solving problems as we want to be referred to as "smart" rather than "big spenders" or "niche players".
Good content
Our solution to this problem is to identify and index only good content rather than junk that is present on almost any web page - some have more of it and some less. Lets define what this good content actually is: good content is unique data that is the final destination. Two key elements are explained in detail below:
- Unique data
Most pages consist of elements repeated on all of the pages for a given site, ie: header, footer, navbars etc. All these elements have no value for search engine that wants to drive user to unique content fitting best user query. Note that we are not talking here about global uniqueness of the page content - global similarity algorithms of the search engine should take care of this, however ensuring that page only has locally (site-wide) unique content will greatly help filtering duplicate content as well as detecting material page changes.
- Final destination
Due to the interlinked nature of the web many sites can be viewed as trees - they have branches with smaller branches that ultimately end with leaves. A good example is your average portal page with a bunch of links: the whole purpose of that page is to lead user somewhere else (either off-site (typical for spam pages and directories) or in-site (typical for content sites)). This is not what we want - what we want are the deep pages with good content (however small it is), an example of which would be this article - this text is good content, but if I had another page with the list of articles linking here then it would not be the final destination for relevant keywords, but this article is.
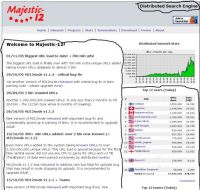
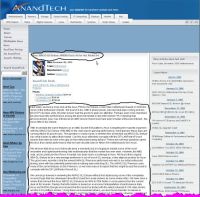
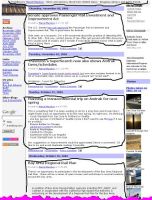
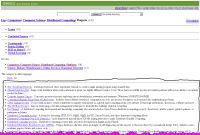
It is best to see once than read 100 times and its certainly 1000 times easier to explain intuitive concept of good content on pictures that can be seen below.
Call you attention to very crudely drawn black boxes that in my view denote good content on these pages. Remaining parts of these pages are either dedicated to navigation or contain clusters of ads that may be valuable to the human visitor of a website using browser but totally worthless to the search engine.
Ignoring junk
So, now we know what needs to be done - identify good content on a given page and discard the rest. Humans can do it without thinking, surely we can achieve reasonable results using computers? Easier said than done you may think, but we have made some progress in this area.
Content Analyser (ConAn)
ConAn is Majestic-12's Content Analyser - software that uses a range of heuristics and visual-based analysis to identify good content on a given page. It is a generic browser-like analysis program that is not aware of specific properties of any page. In other words there are no page-specific patterns allowing to recognise content on say The Times website. It should be stressed that it is not finalised and will improve greatly. The purpose of this article is to bring attention to the topic and test the software before it is put into actual use by Majestic-12 Distributed Search Engine. Note that the software is currently hosted on development server that may be down at certain points of time, but if you retry it later then you should succeed.
Let's see how ConAn deals with the websites shown below (clicking links will open new window with the analyser's output screen):
- AnandTech
- The Register
- The Times
- Train blog
- DMOZ category
- Majestic-12 (note: the table with scores may be judged as junk in later releases)
- Majestic-12 - this article
As you can see ConAn extracts good content pretty well. You can try it on your own websites by using ConAn's control screen. Note that supplying secondary URL would result in cleaner outputs - this is how it will be used after release so don't be lazy and specify secondary page!
Conclusion
We want to be smart when solving serious problems and in this case we found a solution that will greatly reduce costs of building a major search engine, increase its relevance and performance, and results in less spam. Death to endless clusters of links - long life to good content!
Q&A
Below you can see some anticipated questions answered.
- Does it mean that pages that are just full of links will never be found?
No. What it means however that pages full of links (portals and spam sites) will have to rank well on the basis of page title and its query independent rank (ie PageRank). Additionally these pages will not be able (the way they do now) to affect ranking of other sites by selling or exchanging links - natural linking (like the one from this article) on the other hand will be more valuable.
- Does it mean that some text on pages won't be indexed
Technically yes. The elements that will be ignored are junk like clusters of links that have no purpose apart from leading visitor away from that page.
- Does it mean that no link text will be indexed?
No - only clusters of links that exceed internal thresholds will be dropped. Good content has perfect right to contain some natural links to other sites, which is not the same as just a bunch of links with no text.
- Does it mean that ignored links will prevent those pages from indexing?
No. While link text will be ignored actual pages the links are linking to will be retrieved in due course and same logic will be applied to them: only good content from those pages will be added while junk will be thrown away.
- Got a question but too afraid to ask?
Don't be then - ask away in forum!
|