About Majestic-12This is the story of how Majestic went from a back-bedroom company to launching MajesticSEO - now Majestic, a leading provider of web based internet data.
Before the launch of MajesticSEO in 2008, Majestic-12 Ltd relied upon the genius of it's founder, Alex Chudnovsky, and a crowdsourced team of volunteer "web crawlers" who provided bandwidth and operated crawler software.
This is their story.
Alex's interest in search began in the late 90's, during his MBA program. His initial efforts, however, were rather crude. As part of his research into other post-graduate opportunities, he wrote a small tool to allow people submit their GMAT grades in order to try to get some statistical information on who gets into those Unis and who does not. This was fronted by a search engine. Alex refers to this as "a pathetic attempt that used 'table scanning' approach: works okay on small data scales but very wasteful when number of documents increases."
A failed attempt to get into Havard later, and Alex found himself at the bleeding edge of email marketing in a major UK e-retailer at the peak of the first dotcom boom.
After a couple of years service, a technology migration project gave Alex the chance to return to search. His reputation for getting things done saw him prototype an effective search engine for the retailer. Alex continues:
"The search engine that they implemented to search over 500k products was as bad as what I had initially in my first search engine - but this time it used J2EE, something that must have made it look more professional, and certainly a lot more expensive. The core of the search was based on a table scan similar to 'select * from Products where Keywords like '%KeyWord%'"
"It is hard (if possible at all) to do it worse then that: this algorithm is particularly bad in cases when one or more of the keywords is wrong, which would make database scan whole table before not finding anything - a handful of pointless queries could hit site very hard and effectively allow bad chaps execute a DoS attack on an e-commerce site."
"The box that was running database had 12 CPUs and they were running at around 75-80% - way too high, so I took that as a chance to play around some of the newer approach that I invented to make searching faster: basically we need to go away from table scanning and ideally decide quickly if some keywords will never result in any matches, so we can abort searching quickly."
"Products were already referenced by a unique integer product ID, so it was only logical to turn keywords into numbers: a simple Perl script took product IDs with keywords and tokenized keywords converting them into unique WordIDs thus creating lexicon or dictionary. This allowed to do a very quick lookup in the dictionary which was kept as a separate data table with unique index on keyword that allowed very fast determination of either whether we have got some keywords that are not present at all (made up queries that are probably designed to DoS us), or have WordIDs for keywords that we need to search for. Later, when I started reading up on relevant research papers, I found out that this approach is called Inverted Index."
After providing a proof of concept, Alex's colleagues programmed the new code, resulting in a significant decrease in database load and customer delighting sub-second search times.
This project re-ignited Alex's interest in search, and marked a pivot in his career from a business orientated data analyst to search developer.
No employment lasts forever - this is certainly true of those working for dotcom businesses around the millennium. Alex moved to another UK e-retail business to focus on email marketing.
This role failed to stimulate Alex sufficiently, and after a few years, Alex decided it was time start his own business. He turned to a project he had heard of long before - a competition run by Google.
In 2002, Google ran their first programming contest ( Link now 404's - copy available on internet archive ). Alex wasn't interested in a programming contest, but the data made available for the contest intrigued him. However, this curiosity was not to be rewarded - unfortunately, by the time Alex was ready to spend the time to look at the data, it had disappeared.
Never one to let a small impediment get in his way, Alex decided to recreate the data independently, initially writing and running his own crawler.
Attracted by emergent platforms like SETI@home, Alex developed an idea to build a distributed search.
As a self-funded venture, the intial forrays into big data were a little "ad-hoc". Everything was Alex's responsibility - from company accounts to configuring networks and supporting the ever growing number of volunteers. A photo from this period of some of the research machines and the clusters are shown below:

After months of hard work, Alex had developed a distributed web crawler, which was launched onto the world on the 1st January, 2005. The ambitious nature of the project attracted a number of volunteers, and a community soon developed around the Majestic-12 distributed search project.
Managing the community presented challenges as well as benefits. A worldwide community demands around-the-clock support. Alex's time was stretched as he attempted to balance participating in and supporting the community, with automating manual processes and developing the project. Community members helped with feedback, suggestions and even a manual for the distributed software.
Amazingly, despite an increasing workload, Alex found time to work on a prototype search engine. Work began in June 2005, continuing until Spring 2007. This was a far from trivial effort, as shown in the graph of the size of the search engine below ( measured in indexed pages ).
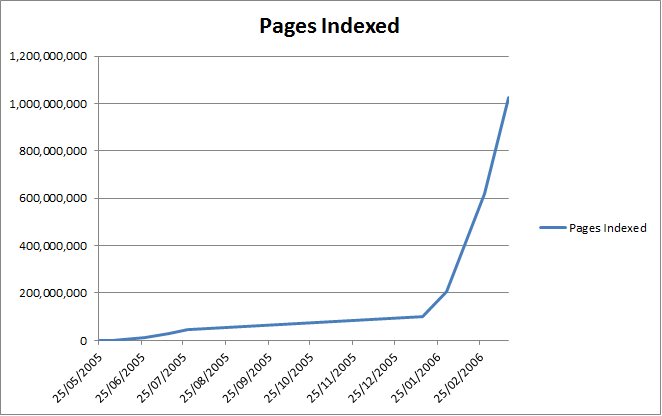
From Humble beginnings, in 2006, Majestic Search grew to have a capacity to search over 1 Billion pages, with the content updated regulary.
By 2006, news of Alex's endeavour had begun to spread beyond technical columns. He was contacted by Michael Pollit, a freelance technology writer, whose article on Majestic-12 was published in the Guardian Newspaper.
A year later, in Summer 2007, work on the search engine had slowed, and Alex's main occupation was developing DSearch. Dsearch was a platform which had acheived a distributed crawl, and was hoped to become, a competitive Web scale search engine based on distributed computing principles with the help of community of people all around the world.
Running a distributed project and developing technology became increasingly demanding on Alex's time.
By late 2007, Alex began to realise that he had reached a threshold - after putting so much effort into the project, it had now reached a point would take more than he could achieve single handed to avoid the project becoming a rather expensive failure. He needed to find new sources of funding and more resource to invest in his project if it were ever to be anything other than a footnote in history. In 2008, Alex began to develop a commercial derivative of his research into search - a backlinks index at Majestic SEO*. The Majestic search engine ran until early 2010, when the experiment was retired to focus resources elsewhere.
* In an October 2014 rebrand "Majestic SEO" became "Majestic", with the majesticseo.com website moving to it's new home at Majestic.com.
| 